Date: 1/1/2020Category: Go编程Tag: Golang, Go-Kratos
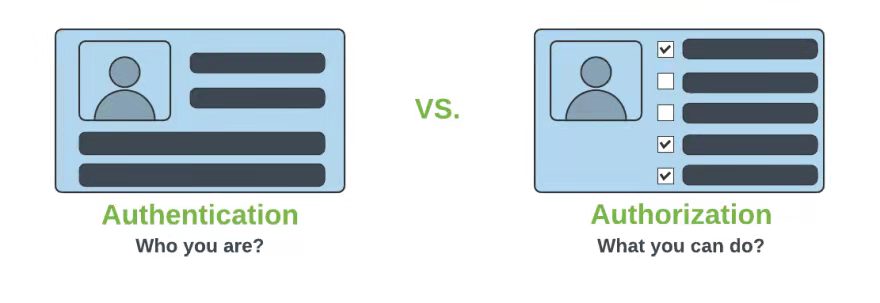
在 Go 语言微服务生态中,单一框架的能力边界往往决定项目上限,而 “核心框架 + 生态扩展” 的架构协同性,才是长期支撑业务迭代的关键。面对 Gin、Go-Micro、Kitex 等选项,go-kratos 不仅自身架构卓越,更通过kratos-transport(通信扩展)、kratos-authn/authz(安全扩展)、kratos-cli(工具扩展)及go-wind-admin/cms/go-crud(应用模板),构建了 “核心定义标准、扩展补全能力、应用落地业务” 的全链路架构体系。本文从架构视角拆解这一生态,解析技术选型优先选择 go-kratos 的深层逻辑。